Biped Ground Station (BGS) UI Design for a Self-Balancing Robotics Platform
As part of the CS 465 User-Interface Design team, we designed Biped Ground Station (BGS) — a user interface that streamlines the tuning and monitoring process for Biped, a two-wheeled self-balancing robot used in the University of Illinois’ embedded systems labs.
Our primary design goal was to simplify controller parameter tuning and real-time performance visualization, replacing a tedious firmware-flashing workflow with an intuitive interface. The design process emphasized efficiency, clarity, and error-free iteration, informed by feedback from educators, researchers, and engineers working directly with Biped.
Implementing Role-Based Access to Matter Device Logs
As part of the CS 598 IoT Security and Privacy course at the University of Illinois Urbana-Champaign, our team — Abdulrahman AlRabah, Ben Civjan, Shalni Sundram, and Sam Yuan — developed a system that introduces role-based access control to the Matter smart home protocol. The project addressed the lack of fine-grained permissions and consistent logging within smart home environments by extending Matter’s Home Assistant integration.
Our implementation enriched Matter’s device logs with structured metadata, enabling controlled visibility based on user roles and permissions, and provided a web interface for managing user groups and viewing filtered logs directly within Home Assistant. The project was tested in collaboration with Dartmouth’s IoT research lab, where it successfully demonstrated secure and scalable access to Matter device data.
This work was later presented at the SDIoTSec’24 Workshop, where it won the Distinguished Paper Award for its research contribution and implementation quality.
Survey: User Authentication and Access Control in Smart Home Devices
Our team in CS 424 Real-time and Cyber-physical & Systems (Abdulrahman AlRabah, Imaad Zaffar Khan, Amaan Aijaz Sheikh) — conducted a survey of 21 papers on authentication and access control for smart home devices. We synthesize trends across authentication mechanisms (passwords, biometrics, multi-factor, behavioral, voice/facial), access control models (RBAC, ABAC, and context-aware hybrids), and privacy practices (transparency, consent, data protection) while analyzing trade-offs between security and usability. The study highlights key challenges—interoperability across heterogeneous devices, scalability/manageability of policies, and observability for debugging—and identifies promising directions such as AI-driven adaptive authentication and anomaly detection, context-aware policies, hybrid RBAC+ABAC designs, and user-empowering interfaces for managing multi-user households.
In MP1, we utilized the Waymo Open Dataset to simulate autonomous vehicle camera perception and designed scheduling strategies using bounding-box prioritization (based on area and depth) to optimize response times.
In MP2, we extended this work to real-world hardware using the NVIDIA Jetson Nano, deploying YOLOv8 for real-time object detection under resource constraints. Through iterative implementations — including inversion-based task scheduling, de-duplication across frames, and spatial hashing for optimization — we achieved substantial improvements in average response time and runtime efficiency (over 30 % reduction compared to baseline).
Conducting Experiments and Implementing Optimizations for the Standard and Mobile Vision Transformers
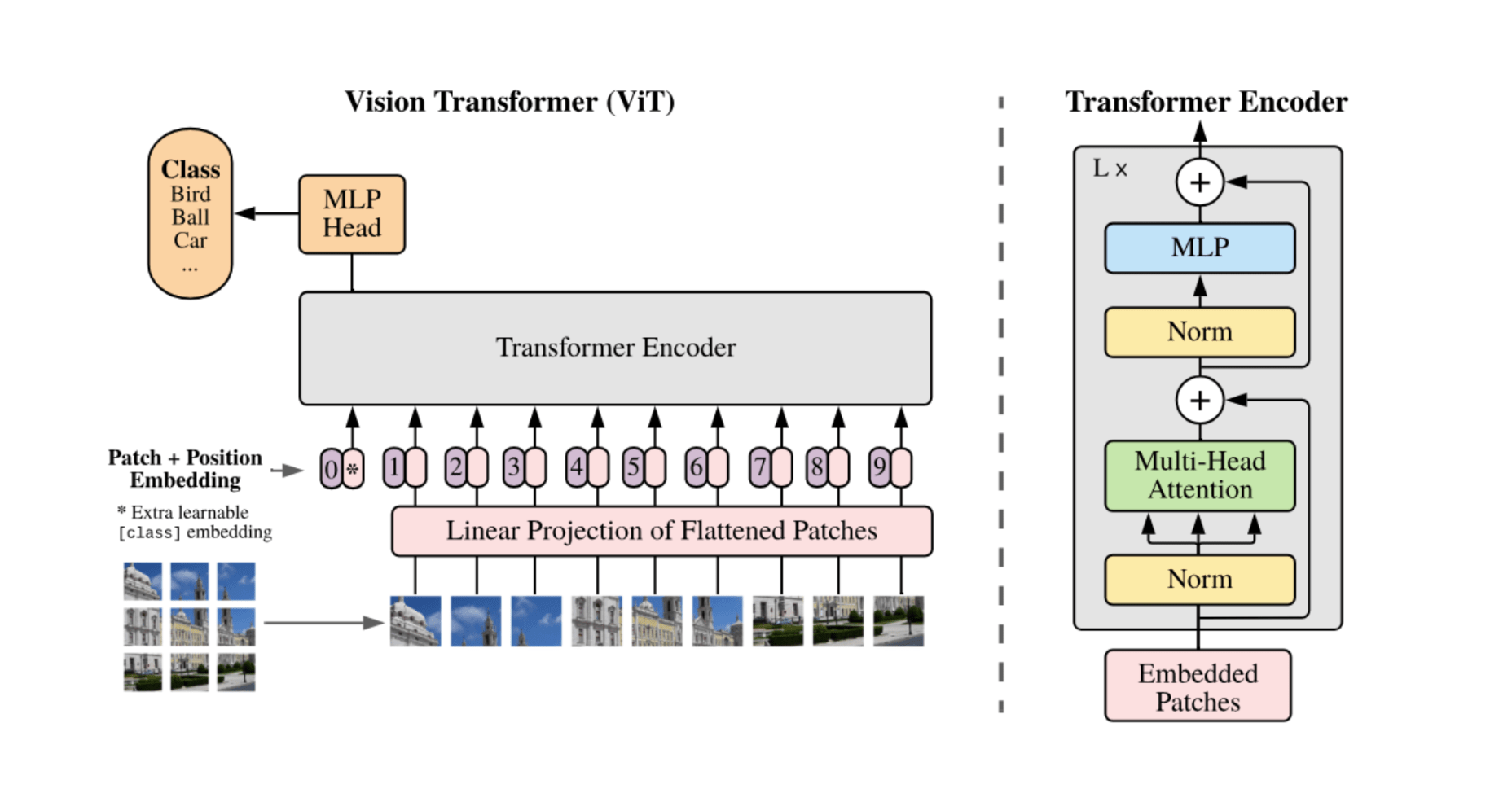
In CS 444 – Deep Learning for Computer Vision our project members are — Ben Civjan, Ritvik Avancha, Abdulrahman AlRabah and Divyansh Chaudhary. We conducted an extensive experimental study of the Vision Transformer (ViT) and its lightweight variant MobileViT, exploring architectural optimizations and their effects across datasets such as CIFAR-10, Fashion-MNIST**, and MNIST. The project investigated the performance of the standard ViT alongside two key optimizations: a convolutional stem (replacing the patchify stem with stacked 3×3 convolutions for better stability) and a specialized positional encoding inspired by the original Attention Is All You Need framework.
We implemented and compared the standard ViT, ViT + Convolutional Stem, ViT + Optimized Positional Encoding, and MobileViT architectures under identical experimental conditions. Results showed that the **convolutional-stem ViT achieved the best accuracy and stability, outperforming the baseline on all datasets while maintaining training efficiency. MobileViT, despite its compactness, demonstrated competitive accuracy and faster convergence, making it suitable for resource-constrained environments such as edge or mobile devices.
Through this work, we demonstrated that careful architectural refinements—particularly in patch embedding and convolutional preprocessing—can significantly improve both the efficiency and generalizability of transformer-based vision models.
Analysis of SQL, NoSQL, and a Hybrid Approach for Realistic Data Management using Amazon Reviews Dataset
As part of CS 511: Database Systems at the University of Illinois Urbana-Champaign, our team —Runzhi Ma, Dev Patel, Alex Zheng, Ben Clarage and Abdulrahman AlRabah — conducted an in-depth study comparing the performance and design trade-offs between SQL, NoSQL, and a hybrid database architecture using the Amazon Reviews dataset. The goal was to understand how different database systems handle large-scale, real-time data under varying workloads.
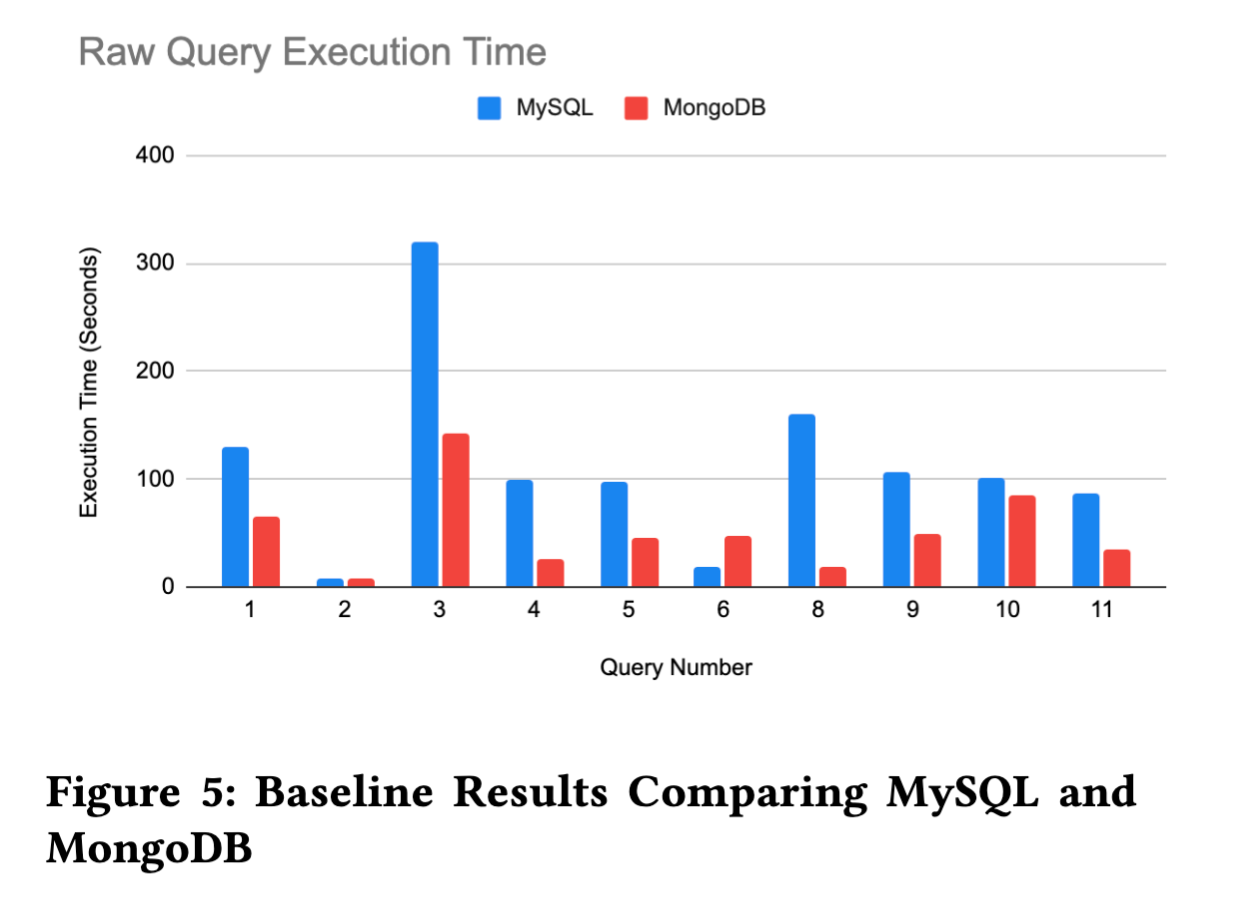
We evaluated MySQL (representing relational systems) and MongoDB (representing NoSQL) through experiments deployed on Google Cloud Platform and MongoDB Atlas. To address the limitations of both systems, we also designed a hybrid model that integrates a buffered streaming layer for optimized inserts and queries. This approach improved isolation and reduced I/O contention, achieving SQL-like consistency while maintaining the scalability advantages of NoSQL.
The results showed that MySQL performed better on complex transactional queries, while MongoDB excelled in high-volume write operations. The hybrid system achieved a strong middle ground, balancing data integrity and scalability with lower latency in mixed read-write scenarios. This project offered practical insights into modern database architecture design and performance tuning for real-world data-driven applications.
Detecting Fake Images Using Visual Cues and Frequency Domain Analysis
As part of CS 543: Computer Vision, our team — Abdulrahman AlRabah, Ajay Rao, Imaad Zaffar Khan, and Manav Singhai — re-implemented the CVPR 2024 paper “Shadows Don’t Lie and Lines Can’t Bend!” and extended it with our own contributions. The project focused on detecting synthetic images produced by generative and diffusion models through geometric and frequency-based cues.
We built a full detection pipeline that analyzes line geometry, perspective fields, and object-shadow relationships, integrating models such as DeepLSD for line-segment detection, PerspectiveFields for vanishing-point consistency, and Detectron2 for shadow segmentation. In addition, we incorporated frequency-domain analysis using Fourier and DCT transforms to expose subtle spectral artifacts introduced during image synthesis. Our extension to the original paper introduced an OpenAI vision fine-tuning component** that classifies real vs. generated images, as well as an autoencoder-based anomaly detector for reconstruction-based fake image discovery.
Through extensive experiments on datasets including Kandinsky, PixArt, SDXL, and DeepFloyd, we found that fake images consistently show misaligned shadows, *anishing-point errors, and low-frequency dominance in the spectral domain. Combining geometric and frequency cues yielded robust performance, achieving over 97 % accuracy on “easy” datasets and demonstrating strong generalization to unseen generative models.
This work reinforced our understanding of visual geometry, lighting cues, and frequency-domain analysis — directly connecting theoretical concepts from CS 543 to real-world detection of synthetic imagery.