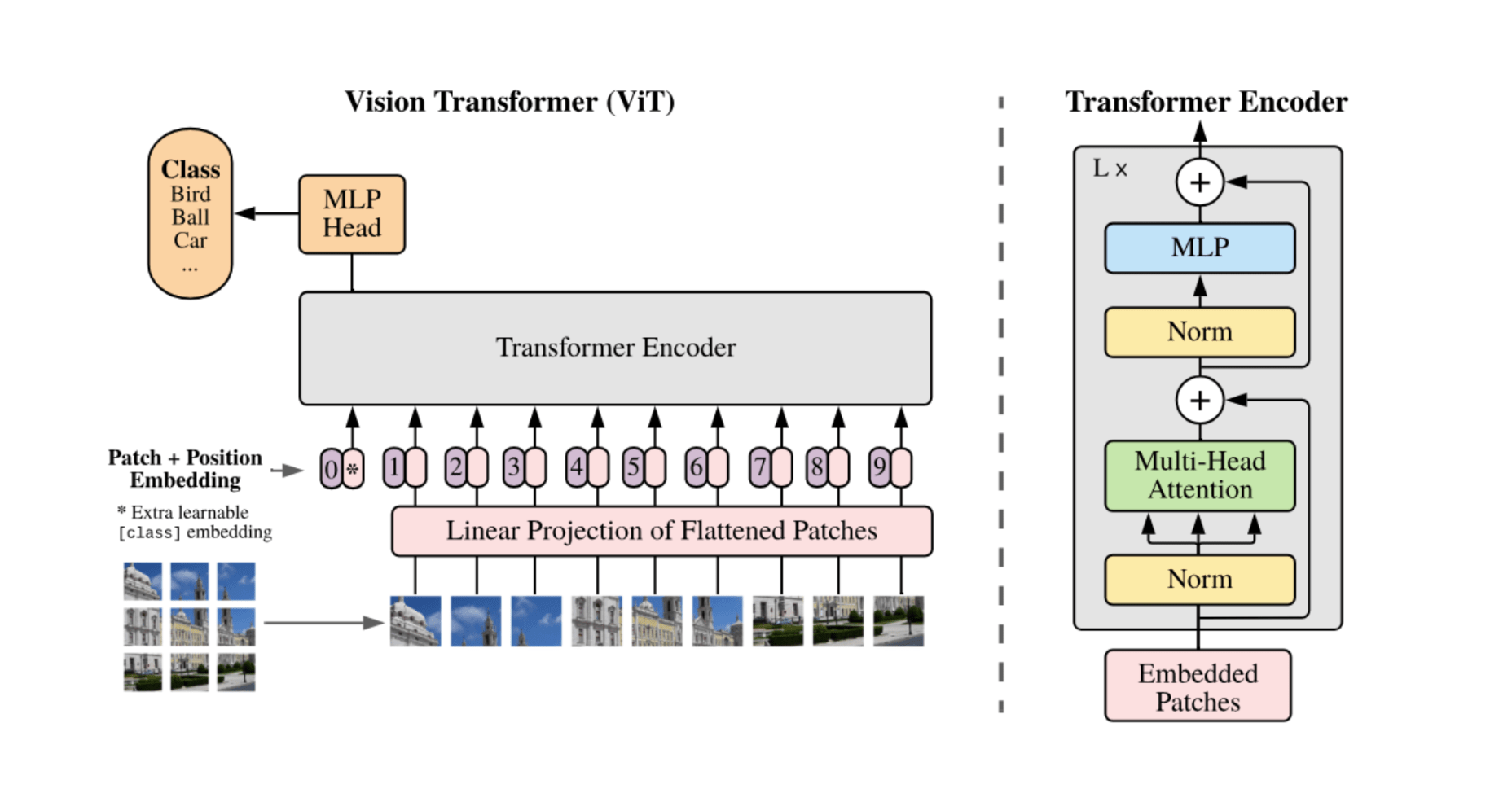
In CS 444 – Deep Learning for Computer Vision our project members are — Ben Civjan, Ritvik Avancha, Abdulrahman AlRabah and Divyansh Chaudhary. We conducted an extensive experimental study of the Vision Transformer (ViT) and its lightweight variant MobileViT, exploring architectural optimizations and their effects across datasets such as CIFAR-10, Fashion-MNIST**, and MNIST. The project investigated the performance of the standard ViT alongside two key optimizations: a convolutional stem (replacing the patchify stem with stacked 3×3 convolutions for better stability) and a specialized positional encoding inspired by the original Attention Is All You Need framework.
We implemented and compared the standard ViT, ViT + Convolutional Stem, ViT + Optimized Positional Encoding, and MobileViT architectures under identical experimental conditions. Results showed that the **convolutional-stem ViT achieved the best accuracy and stability, outperforming the baseline on all datasets while maintaining training efficiency. MobileViT, despite its compactness, demonstrated competitive accuracy and faster convergence, making it suitable for resource-constrained environments such as edge or mobile devices.
Through this work, we demonstrated that careful architectural refinements—particularly in patch embedding and convolutional preprocessing—can significantly improve both the efficiency and generalizability of transformer-based vision models.